2回目の登場の中塚です。おかげさまでメンバー4人みんなで「ほぼ週刊」の投稿を2か月連続で達成することができました。
さて、今回はGmailの特許に関してです。今さら何を? と思われたかもしれませんが、これだけ利用されているシリコンバレー発の技術を取り上げないわけにはいかんだろうと。また、利用しているからこそ、ここに特許があったのか、と多くの人に思ってもらえるかもしれないと期待しました。
ご存知のとおり、GmailはGoogleが提供するフリーのWebメールサービスです。このサービスのローンチが発表されたのは、2004年4月1日です。まだ約13年というべきか、もう約13年が経ったというべきかわかりませんが、私の記憶では、当時はOutlook Expressが広く普及していたと思います。この状況下で、GoogleはGmailについてはたしてどのような特許が取れたのか、それを取り上げたいと思います。
結論から言ってしまうと、この程度の発明が特許になったの?というものが特許になっています。
ローンチの発表前日
案の定というかなんというか、ローンチの発表前日(2004年3月31日)にアメリカで複数の特許が出願されています。目に浮かぶのは、US代理人(ローファーム)が発表期限に追われながら特許出願をドラフトし、なんとか期限に間に合わせることができて安堵しているシーンです。こんな状況は日本と同じですね。
ローンチの発表前日に出願されたものに、10/816427(“427”)及び10/816428(“428”)の二つがあります。リンクを貼っておきます。
427と428は、最終的に特許として認められました。また、いずれも、複数の出願に派生され、複数の特許が生じています。つまり、もともと一つの出願だったものが、ファミリーを形成し、一つのファミリー内で複数の特許が成立しています。
427と428の各ファミリーは、同じUSローファーム(Morgan, Lewis & Bockius LLP)が代理人になっています。実は、このUSローファームは、私がシリコンバレーにいたときに在籍していたところです。そして、在籍中に、427ファミリーの一つについて権利化業務に携わらせてもらいました。米国特許庁の審査官とTelephone Interviewをした記録に小職の名前も載っていて、なんとも懐かしい思い出です。
Gmailに関する特許は数多くありますが、今回は、個人的に馴染みのある427ファミリーの特許を見てみたいと思います。
427ファミリー
家族構成は以下の通りです。
| 出願番号 | 出願日 | 特許番号 | |
| 親① | 10/816,427 | 3/31/2004 | 7,814,155 |
| 子① | 12/892,839 | 9/28/2010 | 8,700,717 |
| 子② | 12/892,842 | 9/28/2010 | 8,626,851 |
| 孫① | 14/243,815 | 4/2/2014 | 9,418,105 |
| 孫② | 14/055,572 | 10/16/2013 | (審査中) |
親一人、子二人、孫二人となっています。具体的には、親①(427)から子①、子②が生まれ、その後、子①から孫①、孫②が生まれました。孫②を除き、特許が成立しています。現在、孫②は審査中です。孫②はさらに別の特許出願へと派生させることができます。したがって、親①から見ると、ひ孫も望める状況となっています。
親①は、出願から6年以上が経った2010年10月12日に特許として成立しました。経緯をみると、審査官から計4回のRejection(拒絶理由通知)を受けていました。頑張って権利化にこぎつけることができた、といったところでしょうか。
ちなみに、427ファミリーについては、外国出願がされておらず、外国では権利化されていないようです。
親①はどこが特許なの?
特許の範囲は、特許出願書類のうち、Claimの記載に基づいて定められます。例えば親①のClaim 7の記載は以下となっています(下線追加)。
|
7.A method of searching messages, comprising: |
Claimの英文の記載形式は独特なため、慣れていないと、意味不明な英語に思えてしまいます。。。上記をすべて日本語に正確に訳すと、それはそれでポイントがわかりにくくなりそうなので、ポイントにフォーカスしたいと思います。
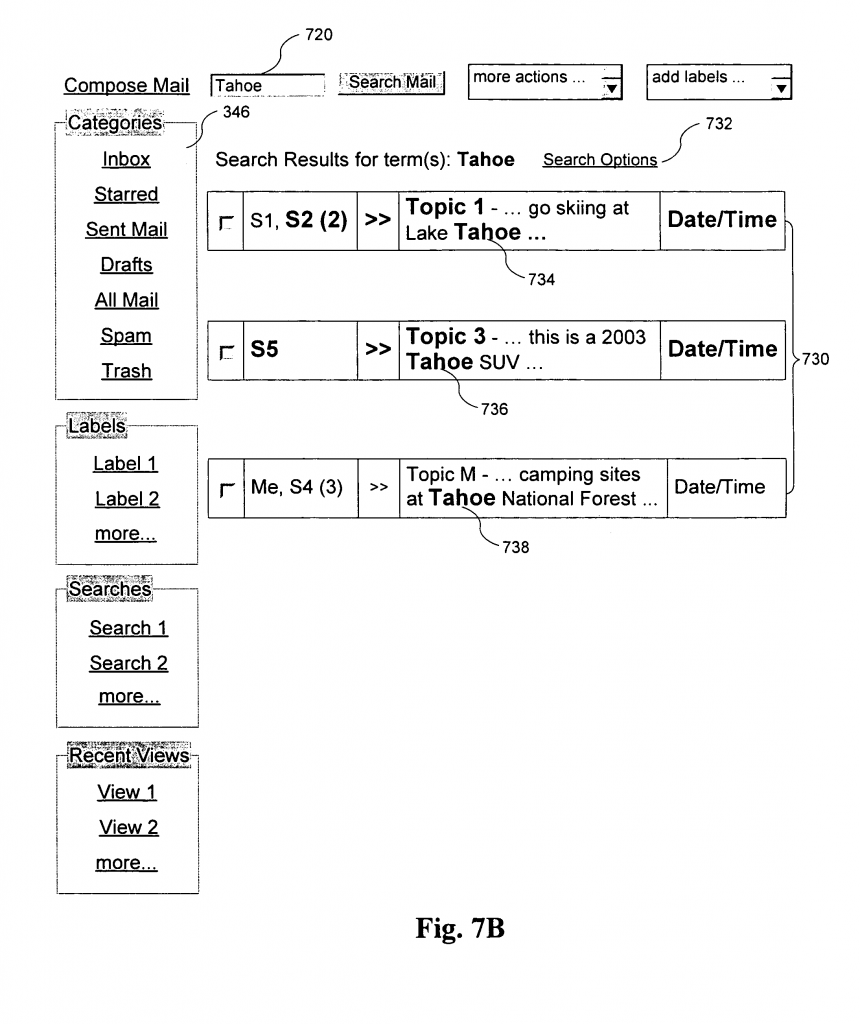
親①のFig. 7Bに照らして、非常にざっくりいきます。親①では、サーバーが以下の処理を行うことが特許になっています。
- サーチクエリー(検索単語:Tahoe)に関連する二つ以上のメッセージを特定する、
・ここで、メッセージは、それぞれ、複数のカンバセーション730の中の一つに関連したものである、 - 複数のカンバセーション730のリストを作る、
- サーチ結果として、そのリスト中の複数のカンバセーション730の各々が、一つのアイテムとしてクライアント端末に表示されるようにする。
「カンバセーション」は関連メール(例えば、往信メールと返信メール)をまとめたものを指す、と理解すればイメージがわきます。
Fig. 7Bに戻りますと、3つのカンバセーション730(1番目:Lake Tahoeへのスキー、2番目:Tahoe SUV、3番目:Tahoe National Forestのキャンプ場所)のそれぞれが1行で表示されています。
このように、サーチクエリーが入力されると、それに関連するカンバセーションが1つのアイテム(1行)として表示されるようにした、というのが親①の特許のポイントです。
こんなのが特許なの?という声が聞こえてきそうですが、はい、これで特許になっています。この特許の機能は実際のGmailに搭載されています。なるほど、たしかに便利な機能です。
427ファミリーは、Gmail上でユーザからのサーチクエリーの入力を受けた場合に、サーチ結果をどのように表示させるか、という点に主眼がおかれています。それでは、子供と孫も見てみましょう。
子①はどこが特許なの?
子①のClaim 1の記載は以下です(下線追加)。
|
1.A method of searching conversations, comprising: |
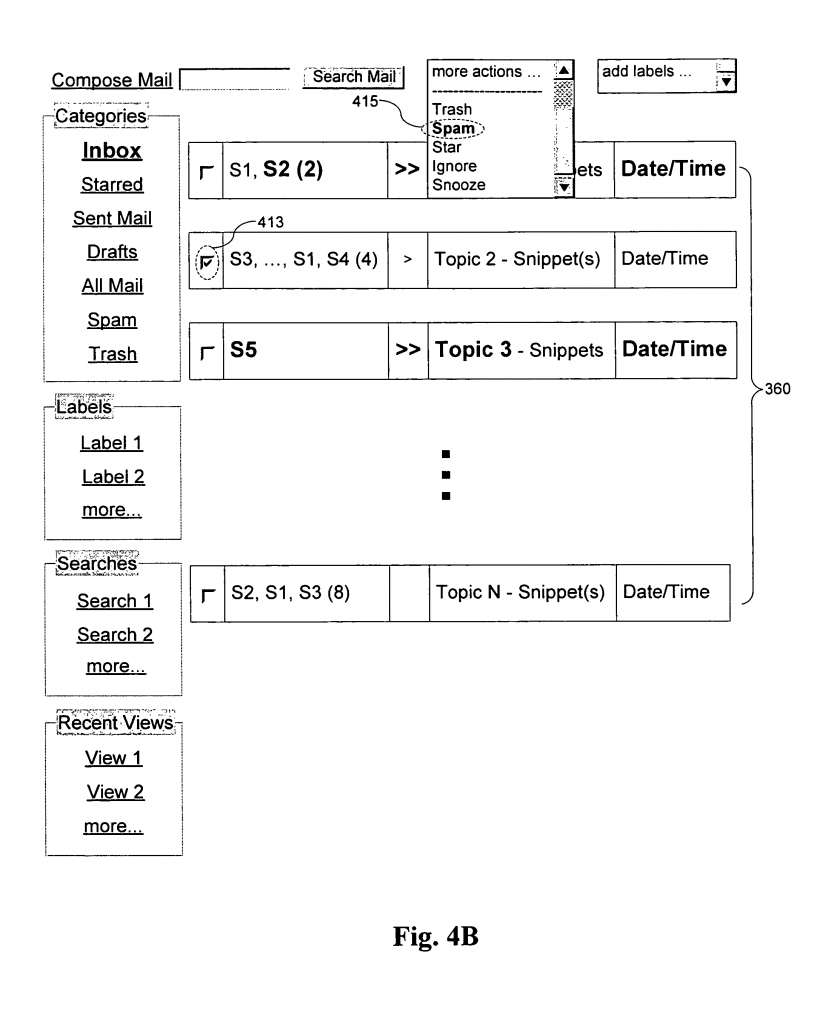
同様に、非常にざっくりと、子①のFig. 4Bに照らしてみますと、サーバーが以下の処理を行うことが特許になってます。
- サーチクエリーに関連するカンバセーション360を特定する、
・カンバセーション360は、二つ以上のメッセージを含んでいる、 - サーチ結果として、特定したカンバセーション360に対応するカンバセーション情報をクライアント端末に表示のために返す、
・カンバセーション情報は、snippet(メッセージ本体部の部分)を含んでいる。
要するに、子①の特許のポイントは、サーチクエリーが入力されると、それに関連するカンバセーションのsnippet(※このカンバセーションに含まれている二つ以上のメッセージにおける一つのメッセージのメッセージ本体部の部分)が表示されるようにした、というものです。
snippetという言葉は、IT業界以外ではあまり聞きなれないと思いますが、ここではカンバセーションのトピックの簡単な説明といったニュアンスでしょうか。snippetに関し、子①の明細書には、カンバセーションの内容のプレビュー、カンバセーションにおける最新のメッセージから作られたもの、カンバセーションにおける最初のメッセージから注出されたもの、カンバセーションにおけるすべてのメッセージから注出されたものなどと記載されています。
The snippet provides the user with a preview of the contents of the conversation without the user having open the conversation. In one embodiment, the snippet is generated from the most recent message in the conversation. In another embodiment, the snippet is extracted from the first message (i.e., the oldest message) in the conversation. In yet another embodiment, the snippet is extracted from all the messages in the conversation according to predefined heuristic rules, e.g., listing a set of keywords appearing most frequently in the conversation. If the conversation management system 102 is preparing a list of conversations in response to a search submitted by the user, it creates a snippet including a highlighted portion that matches the user-submitted query terms at step 322, which may be similar in one or more respects to the snippets included search results returned by a search engine such as the Google™ (trademark of Google Inc.) search engine.
実際に小生のGmailで試してみると、確かにsnippetが表示されます。しかも、snippetが、最新のメッセージの一部だったり、複数のメッセージの一部がそれぞれだったりと、いろいろな態様で表れます。
子②はどこが特許なの?
まず、以下のFig.7Bを再度見てください。一番上のカンバセーションに「S1、S2 (2)」とあります。これは、このカンバセーションにおいて「S1」、「S2」がメッセージの送信者であること、「(2)」がカンバセーションに合計で2つのメッセージがあることを意味しています。同様に、一番下のカンバセーションには「Me, S4 (3)」とあり、これは、メッセージの送信者に自分自身とS4がいて、合計で3つのメッセージがあることを意味しています。
子②の特許は、このようなメッセージの総数を示すものです。ではざっくりと言いますと、サーチクエリーが入力されると、それに関連するカンバセーションを、その中のメッセージの総数とともに1つのアイテム(1行)として表示されるようにした、というのが子②の特許のポイントです。
この機能も実際のGmailに搭載されていますね。参考までに、実際の子②のClaim 1の記載は以下となっています(下線追加)。
|
1.A server system, for searching conversations, comprising: |
孫①はどこが特許なの?
孫①の特許は、子①のsnippetの表示をさらに進化させたものになっています。
ざっくり言えば、孫①の特許のポイントは、サーチクエリーが入力されると、それに関連するカンバセーションのsnippetが表示され、このsnippetが、二つ以上のメッセージ本体部の各部分を含み、かつ、サーチクエリーに合致する単語をハイライトさせる、というものです。
子①では、表示されるsnippetが、二つ以上のメッセージにおける一つのメッセージのメッセージ本体部の部分からなる、というものでした。これに対し、孫①では、表示されるsnippetが、二つ以上のメッセージからの各メッセージ本体部の各部分を含むものになっています。加えて、孫①では、snippetにおいて、サーチクエリーに合致する単語をハイライトしています。例えば、上記のFig.7Bに示すように、サーチクエリーとして空欄720に記入した“Tahoe”という単語が、3つのカンバセーション730における各snippetにおいて太字でハイライトされています。
孫①の機能も実際のGmailに搭載されています。参考までに、実際の孫①のClaim 1の記載は↓となっています(下線追加)。
|
1.A method of searching conversations, comprising: |
孫②はどこが特許なの?
孫②は、現在ペンディングです。そのClaim 1はすでに何回か補正されています。現在のClaim 1の記載を見ますと、送信者リストをどのように表示させるかという点に主眼がおかれています。
孫②の現在のClaim 1の英文の掲載は割愛しますが、簡単に言えば、孫②は、カンバセーションを1行で表示し、そこの送信者リストに複数の送信者を送信順に並ばせる、という点で権利化を図ろうとしています。例えば上記のFig. 7Bに示しますように、1番目のカンバセーションの「S1、S2」が送信者リストとなっていて、S1が最新のメッセージの送信者で、S2がこの前のメッセージの送信者という関係になっています。このような機能も実際のGmailに搭載されています。
427ファミリーのように、もとは一つの出願であっても、別の切り口で複数の特許を取ることができ、また、特許を取り続けようとすることができます。競合他社がやっているところや、やりそうなところを権利化する、また、ペンディングの特許出願を残しておいて競合他社をけん制する、このあたりのところはまさに特許戦略です。
Gmail(特許その1)の編は以上です。いかがでしたでしょうか。特許取得のハードルは意外と低いかもしれない、自分のところでも特許取得できるかもしれない、と少しでも感じていただけたのではないでしょうか。次回以降、Gmail(特許その2)があるかどうかは他のメンバー同様わかりませんが、面白そうであればまた取り上げたいと思います。